Video Generation Landscape Analysis: The Road to Informative Video
We tested 2026 SOTA models and found a "usability gap".

TLDR
- We tested 2026’s state-of-the-art (SOTA) video generation models (like Veo and Seedance 2.0) to see if they could create videos that are information-heavy.
- While cinematic generation is flawless, these upgraded monolithic models fail at structural accuracy. Text morphs into “alien glyphs,” and inferred voices raise a representation and privacy concern.
- We are proposing a shift towards a highly modular architecture. By unbundling the creation process, our explored pipeline stitches together specialised components for document parsing, visuals generation, and avatars.
- This modular nature of our pipeline can expand outside of video. By decoupling the “understanding” of a document from the “rendering” of the video, we can evolve towards a “DocToAnything” framework.
The “Informative Video” Gap
The recent AI video generation model, Seedance 2.0, very quickly became viral with its ability to enable users to create high-fidelity movie trailers from a single text prompt. As the AI sensemaker for GovTech, the AI Practice’s role is to prospect whether these advancements can meet public officers’ needs. Consequently, the Multimodal AI team asked this question: Can these models help communicate ideas and present information?
To find out whether these models were actually down for the task of generating explainer videos, we ran some experiments. We tested Seedance 2.0 [1], along with other SOTA models like Google Veo and Kling 3.0. We appended reference speaker images, reference audio, and reference infographics, and prompted the models with our script to create a presentation clip.
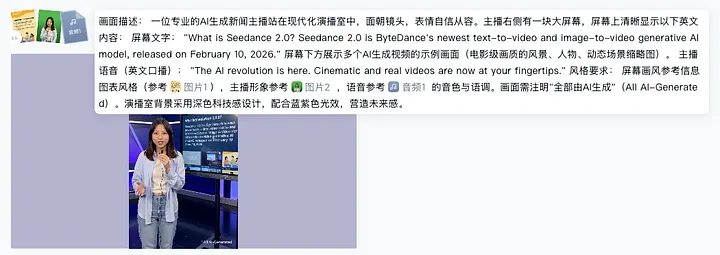
Our experimental setup in Seedance 2.0. We pushed the model’s multimodal capabilities by feeding it a detailed prompt, complete with reference images for the speaker and background, an audio track specifically for voice cloning, and strict textual instructions for the generated screen. We replicated this exact setup for Kling and Veo as well.
Notably, the cinematic aspect of the footage was strong. The generated videos were well-designed, with almost professional camera angles and scenes, accompanied by camera panning that naturally followed the audio of the speaker.
Footages from Kling, Veo, Seedance 2.0
https://youtube.com/shorts/6yCf_FR6aMU?feature=share
https://youtube.com/shorts/Pb0C6eIWnk8?feature=share
https://youtube.com/shorts/SNvMlAeXPrc?feature=share
While the cinematography was great, we quickly hit two roadblocks when it came to making an informative video:
- The “Alien Glyph” Text Problem: SOTA Video Generation models are designed to be “Flow Engines” optimised for smooth motion, exhibiting realism of physics [2]. There is no internal logic dictating the strict spelling of a word across time and hence, pixels inevitably drift. In an AI-generated video, the text tends to morph, and scramble.
Footage of text morphing
https://youtube.com/shorts/L4HvxZiiFpY?feature=share
- The Avatar & Voice Disconnect: Even with reference audio and images, these models work with generated speech. This means that the model just guesses your voice based on how the avatar looks. In Singapore particularly, where the way we talk is unique, this breaks the realism. It also introduces some real representation issues, as when a model infers how you sound based solely on your appearance, it tends to fall back on broad, superficial stereotypes from its training data rather than reflecting authentic voices. Plus, the ability to clone avatars from photos raises identity theft and deepfake concerns. With commercial platforms not being able to easily verify user consent, there are some restrictions to creating real-world avatars natively within these SOTA models [3].
Envisioning this Capability for the Public Sector
Our exploration didn’t actually start with video. We were initially looking at automating the generation of visually pleasing slides directly from raw documents. For slide generation, text rendering is most critical to be able to convey information. This led us to experiment with models that have strong internal reasoning, like Nano Banana Pro, to handle the structural rendering[4].
Once we had a baseline for generating static slides, we naturally wanted to see how far we could push the capability. Could we generate a digital presenter to actually deliver this content? Given the effectiveness of short-form video on social media, we wanted to explore whether we could create engaging, bite-sized content to educate the audience.
However, as we tested the waters of SOTA video generation models, we realised that they struggle to simultaneously balance accurately rendered text and a high-fidelity talking-head avatar. For vastly different public sector needs, we are envisioning a modular solution, one built around utility and control.
A Modular Multi-Engine Pipeline
Instead of forcing a single generative model to do everything, we engineered a modular pipeline. This modular approach directly supports our inclusivity thrust by modularising the video generation approach to create persona-preserving voices and avatar. By treating document extraction, visual generation, and audio synthesis as distinct, swappable blocks, we gained more control over the final output.
- Content Extractor: We use Docling to ingest raw documents (like PDFs). This allows us to preserve the underlying document structure and intelligently extract text, figures, and tables completely intact.
- Content Planner: Leveraging multimodal retrieval, we pull the most relevant extracted components to build a cohesive narrative. This step generates both the structural outline for our visuals and the spoken script for our presenter.
- Visual Generator: We hand the visual outlines off to Nano Banana. It generates textually accurate, hallucination-free background slides and data-driven infographics.
- Avatar & Voice Engine: We feed the generated script into a dedicated lip-sync avatar model, LongCat Avatar. By pairing this with Qwen3-TTSvoice cloning model, we can create realistic avatars, which addresses a limitation of generic SOTA models. This enables us to safely use verified, authentic local Singaporean voices.
- Compositor: Finally, a programmatic video editor (like FFmpeg) stitches the generated presenter side-by-side with the infographics, outputting the final, perfectly synced video.
The Trade-Off: Control vs. Cinema
Of course, our modular approach comes with deliberate trade-offs. If you put an explainer video generated by our pipeline next to a clip from Seedance 2.0, the visual difference is obvious. Our pipeline’s cinematography simply cannot hold a candle to SOTA models; our lighting isn’t cinematic, and our camera angles are fully static.
https://youtube.com/shorts/YHSHWjR5XLk?feature=share
However, there is room to improve this through more creative compositing. Moving forward, we could adopt a hybrid approach: leveraging SOTA video models to generate dynamic B-roll and atmospheric scenes where text isn’t required, and then smoothly transitioning back to our grounded, structurally accurate slides the moment data and facts need to take centre stage.
What’s next? The Pitch for “DocToAnything”
AI development moves at a rapid pace. Whatever we find lacking for now, six months later, a new monolithic model update might solve text grounding or safer voice cloning. But at this time of writing, these are our observations.
More importantly, building this modular pipeline led us to wider scope in the content generation space. Having successfully decoupled the “understanding” of a document from the “rendering” of the final output (Nano Banana / Avatars), we aren’t just limited to explainer videos. We can make infographics, executive summaries or podcasts even.
This architecture sets the stage for a “DocToAnything” framework. If the core engine can accurately read, structure, and synthesise a dense 30-page PDF, the output format becomes entirely interchangeable and these are some ideas we have:
- DocToPres: Automatically generating the slide deck.
- DocToShortVideo: Generating the explainer video with an avatar.
- DocToInfographic: Generating visually appealing infographic encompassing the main points.
- DocToPodcast: Swapping the avatar for a multi-speaker audio discussion.
- DocToBrief: Generating a localised executive summary.
Conclusion
The fast-moving nature of the AI video and content generation space makes this work incredibly exciting. Given that almost every public officer creates some form of materials for communication of ideas in their daily work, the potential for productivity gains is immense if we can reliably generate more corporate-ready materials. By automating the heavy lifting of beautifying slides, structuring data, and producing content for dissemination, we can free up officers to focus on the message itself rather than the medium.
Our team at AI Practice would be keen to connect with any Singapore Public Sector teams that are also exploring AI for informative content, or if you see the potential of the DocToAnything framework for your own workflows. Reach out to us to see the pipeline in action, or just to share your own learnings!
P.S. If you want to know more about this space, we just launched a comprehensive Multimodal AI Handbook. Feel free to check it out at https://go.gov.sg/mmhandbook!
References
- ByteDance. (2026). Seedance 2.0 Official Page. Link
- Liu, Jung-Hua. (2026, February 9). From Frames to Worlds: A Comparative Study of Spatial Intelligence in Multimodal Video Generation and Generative World Models. Medium. Link
- Wu, Jessie. (2026, February 10). ByteDance suspends Seedance 2.0 feature that turns facial photos into personal voices over potential risks. TechNode.Link
- Barova, Mariam. (2025, November 18). Nano Banana Pro is Here: Full Review and Guide. HiggsField. Link
All sample videos in this post were produced using freemium platforms offering these SOTA models like FreePik, Jimeng and Gemini.