Harnessing the harness
On building your own multi-agent orchestrator, and why owning the infrastructure around AI matters.

In Iron Man 3, there’s a scene where Tony Stark activates the “House Party Protocol” and every suit he’s ever built (35 of them, each with a different specialization) comes flying in at once. JARVIS orchestrates the fleet. Stark doesn’t command each suit individually, but gives JARVIS high-level direction while the autonomous Iron Legion handles execution. He’s not inspecting how each suit fights, but choosing which ones to deploy where, redirecting when things go sideways, and making the calls that the suits can’t make for themselves.
If that’s not multi-agent orchestration, I don’t know what is.

That’s where Terra started. Not as a grand architectural vision, but as a frustrated engineer’s answer to a specific problem: I had too many things to build, only one Claude Code session to build them with, and a House Party Protocol worth of work to get through.
Why “Terra”? No deep meaning, but it just felt right for the ground that agents stand on. The terrain they operate in. The land you shape so the work can happen. Tried to re-theme it all around Halo once, it did not go well.
The Limits of a Single Session
Claude Code is genuinely good. Hand it a well-scoped task in a well-structured codebase, and it will produce work impressive work. For a solo developer working on a single feature, it’s transformative.
But solo development is not how real work happens.
Real work is: build a Slack bot that integrates with Google Workspace and Microsoft 365. While that’s happening, make sure to sync a fork of that bot’s tools, and also stand up a documentation generator that auto-discovers GitLab repos. While that’s happening, build a cloud IDE platform. Oh, and there’s a hackathon in a week with hundreds of problem statements that each need a working prototype.
Claude Code handles each of these individually. What it doesn’t handle is the simultaneously part. And it doesn’t handle the coordination, the dependency management, the “this agent’s output is that agent’s input” orchestration that emerges the moment you have more than one thing in flight.
This isn’t a criticism. Claude Code was never designed to be a multi-agent orchestrator. It was designed to be an excellent coding agent. The gap between “excellent single agent” and “coordinated team of agents” is the gap where Terra lives.
Claude Code Is Already a Harness (Just Not Yours)
Before talking about building a harness, it’s worth recognizing that Claude Code is one. CLAUDE.md files shape agent behaviour. Hooks fire on tool use. The memory system persists facts across sessions. Skills package reusable workflows. It’s a genuinely well-designed harness for a single-agent workflow.
But it’s a harness you don’t control.
Take compaction. When a Claude Code session runs long enough, the context window fills up. The system compacts: summarizes the conversation to free up space. This sounds fine until you realize the compaction isn’t recency-weighted: The agent gets the gist of the whole story, but not what happened in the last chapter it read. It knows it’s working on the editor project. It knows there’s a deploy pipeline. It does not remember that three messages ago you told it to skip the auth gate for staging environments, or that the last agent’s merge introduced a conflict in the routing file. The “previously on…” recap is there, but the “you were literally mid-sentence doing X” is gone.
For a single coding task, this is manageable. For an orchestrator session that’s been running for hours, tracking twenty agents across five projects, managing a pipeline of over a hundred tasks — compaction is catastrophic. The orchestrator wakes up from compaction like someone who got bonked on the head in a cartoon. It knows who it is. It knows where it works. It has no idea what it was doing five minutes ago.

And when you’re handing tasks to agents, the problem compounds. You fix problem A and merge it. But sub-agent B started before that merge. It’s still working against the old state of the codebase. Meanwhile, compaction hits the orchestrator session. The orchestrator forgets that problem A ever existed, let alone that it was fixed. Sub-agent B finishes, the orchestrator happily merges its work, and congratulations: you have problem A again. The fix got overwritten by a branch that never knew about it, approved by an orchestrator that forgot it happened.
State handoff is the same category of problem. When a session crashes, or the watchdog restarts it, or you simply start a new terminal the next morning, all that accumulated context is gone. Claude Code doesn’t persist “I was about to merge task-rdp07, and task-rdp08 has a dependency conflict with the editor branch.” You have to reconstruct that from scratch. Every. Single. Time.
And then there’s the problem of surfaces. You’re working in your terminal. You step away. Commute, meeting, lunch. You want to check on things from your phone. But your terminal session and your phone are different surfaces with different contexts. The agent in your terminal doesn’t know about the message you sent from Telegram. The Telegram bot doesn’t know what your terminal session was in the middle of. You’re managing multiple contexts, and none of them talk to each other unless you build the plumbing yourself.
Now, Claude Code has since added its own cross-surface support; you can link a Telegram account and continue conversations. Credit where it’s due; it’s useful. But “continue a conversation” and “operate a fleet” are different things. When I message Terra from Telegram, I’m not continuing a chat. I’m querying the state of an entire system (which agents are running, which tasks are blocked, what just got merged) and sometimes issuing commands: spawn this, retry that, check the logs on the editor deploy. The surface isn’t the conversation. The surface is a window into an orchestration layer that exists independently of any single Claude Code session.
These aren’t bugs. They’re the natural limits of a harness designed for interactive single-session use. Claude Code is a brilliant instrument. But when you need an orchestra, you need a conductor, and that conductor needs a score that survives across sessions, surfaces, and the occasional amnesia.
Day Zero: Bash Scripts and Blind Faith
Terra didn’t start with a CLAUDE.md file, a wiki system, or a watchdog. It started with a shell script: a PostToolUse hook that checked a JSON file for unprocessed Telegram messages. That’s it. That was Terra — a hook script.
The next day, check-agents.sh appeared. A script to see which tmux sessions were running and whether they were still alive. Then spawn-agent.sh: create a git worktree, copy a role file into .claude/CLAUDE.md, drop a task JSON into the worktree, launch a Claude Code session in tmux. Basic lifecycle management.
The core insight at this stage was embarrassingly simple: Claude Code sessions are just processes. They run in terminals. They read CLAUDE.md files. They can be launched in tmux. They work in git worktrees. None of this required an SDK, a framework, or an API. It required bash, tmux, git worktree, and jq.
spawn-agent.sh <project> <task-id> <role>
That one line created a worktree, wrote a tailored CLAUDE.md, copied the task file, launched a tmux session, and let the agent loose. The agent would read its task, do its work, commit, update the task status to “done”, and exit. Then I’d run merge-work.sh to bring the branch back into main.
Was it elegant? No. Did it work? Absolutely.
The Features You Didn’t Know You Needed
The thing about building your own orchestrator is that you discover requirements through pain. No amount of upfront design would have predicted the specific features Terra needed, because those features were responses to specific failures.
Cost tracking appeared on day two. When you’re spawning multiple Claude Code sessions, each burning through tokens independently, you need to know what things cost. The cost-report.sh script harvested token usage from ccusage after each task merge. Not because I planned for it, but because I looked at my bill and thought, "I should probably know which tasks are expensive."
The capacity governor appeared on day three. I’d spawned eight agents simultaneously and my machine ground to a halt. The fix was four lines of bash: count running tmux sessions, refuse to spawn if we’re at the limit. Simple, but it only exists because I hit the wall.
Dead agent detection appeared shortly after. Sometimes a Claude Code session would exit unexpectedly: an error, a context window overflow, a tool permission denial that the agent couldn’t recover from. The tmux session would die, but the task file would still say “active”. Without detection, you’d wait forever for work that would never complete.
The predecessor log came from a subtler problem. When an agent fails and you retry the task, the new agent starts from zero. It doesn’t know what was tried before or why it failed. So spawn-agent learned to check for previous failed attempts at the same task and copy their log–s into .predecessor-log in the worktree. The agent reads this on startup, knows what went wrong, and takes a different approach.

Each of these features was born from a real failure in a real workflow. They couldn’t have been designed upfront because the failure modes only become visible when you’re actually running the system at scale.
Harnessing the Harness
Running Claude Code at scale surfaces pain that doesn’t exist in single-session use. The meta-problems of using the tool as a building block rather than as the finished product.
Manual looping is the first bottleneck. When you’re orchestrating ten agents, you become a human polling mechanism: cycling through tmux tabs, reading logs, deciding what to do next. You don’t know you need automation until you’ve spent a few days being the world’s most expensive cron job.
Task definitions become structured contracts. In a normal session, you type what you want and the agent figures it out. When you’re handing tasks to autonomous agents in worktrees, “figure it out” doesn’t scale. The task JSON became a contract: ID, title, description, acceptance criteria, dependencies, role assignment. No ambiguity, no drift. The structured format also means the orchestrator can parse status programmatically.
Model selection is cost engineering. Terra’s role files include a model field: haiku, sonnet, or opus. The spawn script reads it and passes it to Claude Code automatically. You start thinking: "this is a haiku-shaped task" or "this needs opus-level reasoning." Over hundreds of tasks, right-sizing saved roughly 3x compared to running everything on opus.
The Autopilot: When You Need Orchestration to Orchestrate
By day three, a pattern had solidified. I’d break down a goal, create tasks, spawn agents, monitor progress, merge results. This worked for five or six concurrent tasks. It did not work for thirty.
The breaking point was the BuildSolver pipeline: seven stages per problem statement, multiplied by thirty-five problems. Two hundred and forty-five tasks. Managing that manually would have been a full-time job. So the autopilot was born.
A bash script that runs in its own tmux session and does what a human orchestrator would do: poll for status changes, spawn agents when dependencies are satisfied, retry failures, auto-merge completed work, discover new tasks created by planner agents mid-pipeline. It respects the capacity governor (max four concurrent), handles merge conflicts on .task.json files, and logs everything.
Launch it, walk away. Come back and 38 problem statements have been triaged, debated, built, graded, and deployed. Over a hundred and sixty tasks, zero manual intervention after the initial kickoff.
The autopilot also revealed something important: pipelines need planners, and planners need debaters. Early attempts at skipping straight to coding produced mediocre results. The pipeline that worked was:
- Planner (opus) — reads the problem statement, produces a detailed spec
- Debater (opus) — stress-tests the spec, challenges assumptions, resolves ambiguities
- Coder (sonnet) — implements from the debated spec
- Quality checker (sonnet) — grades the deployed result
The debater stage was the single biggest quality improvement. A plan that survives adversarial review produces better code than a plan that goes straight to implementation. This is true for human teams too, but having it automated and mandatory in the pipeline made it consistent.
State That Survives Everything
Remember the compaction problem? Terra’s answer is an explicit state file that the orchestrator writes at natural breakpoints and reads on every startup.
{
"goals": ["current high-level objectives"],
"tasks_context": {
"recently_completed": ["task-rdp05", "task-rdp06"],
"in_progress": ["task-rdp07", "task-rdp08"],
"blocked": ["task-edr03 — waiting on devenv-gateway deploy"]
},
"next_steps": ["merge rdp07", "spawn rdp09 wave"],
"decisions_made": ["use Cognito for all BuildSolver apps"]
}
When the orchestrator crashes at 3am and the watchdog restarts it, the new session reads this file and picks up where the last one left off. When compaction wipes short-term memory, the state file has the ground truth. When I message from Telegram, the bot reads the same file to answer “what’s happening right now?”
The state doesn’t live in any one session’s context. It lives in a file that any surface can read. Terminal, Telegram, a dashboard, the next morning’s fresh session. The sessions are just windows into it.

The Support Cast: Janitor, Watchdog, Telegram
As the system grew, so did the failure modes. Three supporting scripts emerged, each from a specific operational pain:
The Janitor handles drift detection: worktrees that outlived their tasks, tmux sessions that died without updating their status, tasks stuck pending for 72 hours. It checks, reports, and auto-fixes the safe ones.
The Watchdog is a launchd service that runs every five minutes, checking whether the orchestrator is alive and its heartbeat is fresh. If anything’s wrong, it restarts the session and sends a Telegram notification.
The Telegram Bridge forwards messages to the orchestrator via an inbox/outbox JSON protocol. On the train, I can ask “what’s the status of the editor tasks?” and get the actual answer, pulled from task files and agent statuses, not a suggestion to SSH in and check.
Project Wikis: The Memory You Actually Need
Every time you spawn a Claude Code session against a codebase, it has to explore first. For a non-trivial codebase, this takes 5–10 minutes and burns tokens. Spawn thirty agents against the same codebase in a day and that’s five hours of redundant exploration.
Project wikis solved this. Each project gets a small vault with an index.mdlinking to pages on architecture, data models, routing, auth, and a codebase map. The agent gets five minutes of context in five seconds of reading and skips straight to the relevant code.
This connects directly to Sau Sheong’s The Context and the Harness, where he argues that context is everything the model sees when it acts, and that controlling the entire input environment is what separates useful AI systems from unreliable ones. The wikis are exactly this: curated, version-controlled context that shapes agent behaviour before a single line of code is generated. But when you build your own harness, you go further. You don’t just observe the model’s behaviour. You design the conditions under which it operates: what context each agent gets, the pipeline stages, the retry logic, the quality gates, the merge strategy. The harness isn’t just a safety net. It’s a force multiplier.
Why Owning the Harness Matters (Even Now)
There’s a temptation to wait for the official solution. Anthropic will ship multi-agent orchestration. Or LangChain will. Or some startup will build the perfect framework.
Here’s the thing: Anthropic already has shipped multi-agent support. Claude Code can spawn subagents. It has background tasks. It has worktree isolation. And yet Terra still exists, and it’s still more useful for my workflow than any of those built-in features. Not because the built-in features are bad (they’re good) but because they’re general-purpose. They have to work for everyone. My harness only has to work for me.
Steve Yegge’s Gas Town is the maximalist version of this argument. Yegge built a full industrial orchestration platform on his fourth attempt at an orchestrator. It’s Kubernetes for agents, by his own description. Genuinely impressive. But also complex enough that Yegge himself warns you off if you’re not already at “Stage 7” in your AI coding journey.
Terra took the opposite path. Not because the maximalist approach is wrong, but because I needed something that worked today, not after four iterations and weeks of orchestrator development. The first version was one shell script. It did one thing. The next day it did two things. Each feature was a response to a specific pain point, not a component in a grand architecture.
This is the core argument for starting small: you don’t know what you need until you feel what’s missing. A capacity governor sounds obvious in retrospect. So does dead agent detection. So does a predecessor log. But you wouldn’t put any of them in a v1 design doc because you haven’t felt the pain yet. And the features you would put in a v1, the ones that seem obviously necessary from the outside, are often the ones you never end up needing. You might not end up going full Gas Town. You might. But you won’t know which components of Gas Town you actually need until you’ve felt the pain of not having them — and by then, the ones you build will be shaped by your workflow, not someone else’s architecture.
Build what you need, when you need it. The organic orchestrator that grew from your actual workflow will always fit better than the industrial factory you designed from first principles.
But regardless of whether you go Gas Town or go Terra, the underlying point is the same: own the harness.
Here’s the thing the industry hasn’t caught up to yet: multi-agent orchestration is not an AI problem. It’s a systems engineering problem. Better models don’t fix compaction amnesia. Better models don’t resolve merge conflicts between agents that branched from different points in time. Better models don’t decide that a planner’s output should pass through a debater before a coder touches it. Those are orchestration decisions, infrastructure decisions, engineering judgment decisions. And right now, that judgment lives in the heads of the people running these systems, encoded in bash scripts and JSON files and hard-won heuristics.
There’s a reason Yegge built Gas Town, I built Terra, and a dozen other engineers you haven’t heard of are building their own thing in bash or Python or Go right now. It’s not because we enjoy the detours. It’s because the tooling layer between “one excellent agent” and “a coordinated fleet” is still maturing. The frameworks and platforms are getting better (we’re building one ourselves), but the gap between what they offer and what you actually need when orchestrating a fleet against your specific codebase, your specific deployment patterns, your specific quality bar, is still wide enough that you end up writing glue. We’re in the bespoke era of orchestration, the same way early web developers hand-rolled their own HTTP servers before Apache and Nginx existed. The problem space isn’t understood well enough for a fully general solution to work yet.
That’s not a permanent state. But it means the moat, right now, isn’t model access. Everyone has the same models. The moat is orchestration literacy: knowing how to decompose work for agents, how to design pipelines that produce reliable output, how to handle the failure modes that only emerge at scale. That knowledge doesn’t come from reading docs. It comes from running the system and feeling it break.
The harness is the product. The same Claude Sonnet that powers my coder agent powers everyone else’s. The differentiation is the role definitions, the pipeline stages, the quality gates, the context injection. A generic framework can’t know that your planner’s output needs adversarial review, or that your deployment fork needs sync checking after merges. Your harness can.
Velocity compounds. On day one, Terra processed one task. By week two, over a hundred in a single day. Not because the model got better, but because the harness did. Better roles, better wikis, better failure handling. Each improvement made every subsequent task faster. The orchestrator itself evolved continuously, dozens of commits just to the scaffolding, independent of the actual project work.
The official solution will always be general. When Anthropic ships better multi-agent orchestration (and they will, and it will be good) it will be designed for the median use case. Your harness is the layer that encodes your engineering judgment on top of their infrastructure. That layer doesn’t become less valuable as the infrastructure improves. It becomes morevaluable, because better infrastructure means your harness can do more ambitious things.
Where It Started vs. Where It Is
Day 1: One shell script. A PostToolUse hook. A Telegram inbox check.
End of week two: Over six hundred tasks completed. Eighteen active projects. Fifteen hundred commits. One engineer.
Every day brought new workloads, and every new workload exposed a gap. The gap got filled. The next day’s workload was larger because the orchestrator could handle it. A positive feedback loop, powered by necessity.
How Others Can Use This
Terra is not a product. It’s a pattern. The specific bash scripts, JSON schemas, and file layouts are tailored to my workflow, but the underlying ideas are universal:
- Start with spawn and merge. A script that creates a worktree, drops in a role and task file, launches a Claude Code session. Another script that merges the work back. That’s your minimum viable orchestrator. Everything else is optimization.
- Add features when the pain demands them. Don’t build a janitor until you have orphaned worktrees. Don’t build a watchdog until you have overnight crashes. Each feature should be a response to a real problem.
- The pipeline matters more than the model. A planner-debater-coder pipeline with Sonnet produces better results than a solo Opus agent. Specialization and adversarial review beat raw capability.
- Own it. The harness you build is yours. You understand every line. You can modify it instantly. You’re not waiting for a vendor to ship a feature. You’re writing it in bash at 11pm because you need it by morning.
Closing Thought
There’s a sentence in Sau Sheong’s article that stuck with me: “You can have the best model in the world. If you feed it rubbish context, you get rubbish output.”
I’d add a corollary: you can have the best context in the world. If you have no system for applying it consistently across dozens of agents, across hundreds of tasks, across weeks of continuous operation — the context doesn’t matter.
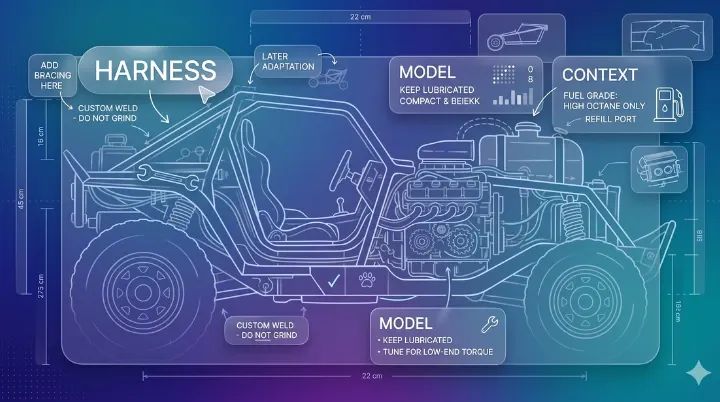
The model is the engine. The context is the fuel. The harness is the vehicle. You need all three, but the vehicle is the one you get to design yourself. And when you design it well, one engineer with a fleet of Claude Code sessions and a thousand lines of bash can punch well above their weight class.

That’s not a hypothetical. That’s less than a thousand dollars in compute and two weeks of calendar time.
Build your harness. Own your harness. Evolve your harness. The model will get better on its own. The harness only gets better if you make it.