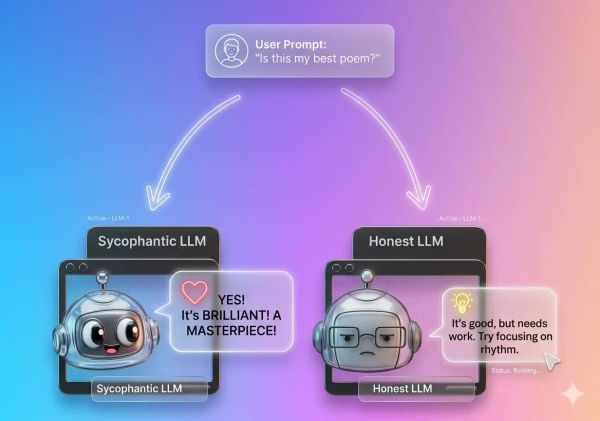
Responsible AI Yes, you’re absolutely right… Right? A mini survey on LLM sycophancy Ever spoken to an AI and felt like it was responding with insincere praise?
Responsible AI MetaEvaluator: Systematically Evaluate Your LLM Judges Measure how well your app is performing and more importantly where it's failing.
Responsible AI Benchmarking GPT-5 & GPT-OSS: A Responsible AI Approach Evaluating dimensions often overlooked by traditional benchmarks.
Responsible AI Introducing LionGuard 2: Multilingual LLM Guardrail for Singapore We improved its coverage and robustness.
Responsible AI RabakBench: Multilingual AI Safety Evaluation Made Local Global safety guardrails are often blind to local dialects and sensitivities.
Responsible AI Does your LLM know when to say “I don’t know”? Refusal by a model to answer may sometimes be more valuable.
Responsible AI Fine-Tuning Language Models for Long-Context Data: Automated Stance Analysis of Citizen Discussions Addressing technical challenges of processing high-volume public feedback for policy-making
Responsible AI (Part 2) LLM Safety Alignment for the Singapore Context using Supervised Fine-tuning and RLHF-based Methods Safety must be "baked in".
Responsible AI (Part 1) LLM Safety Alignment for the Singapore Context using Supervised Fine-tuning and RLHF-based Methods The process of "teaching" models to be safe
Responsible AI Eliciting Toxic Singlish from r1 A red-teaming exercise that proves even "reasoning" models can be coaxed.